Osmunda

Introduction
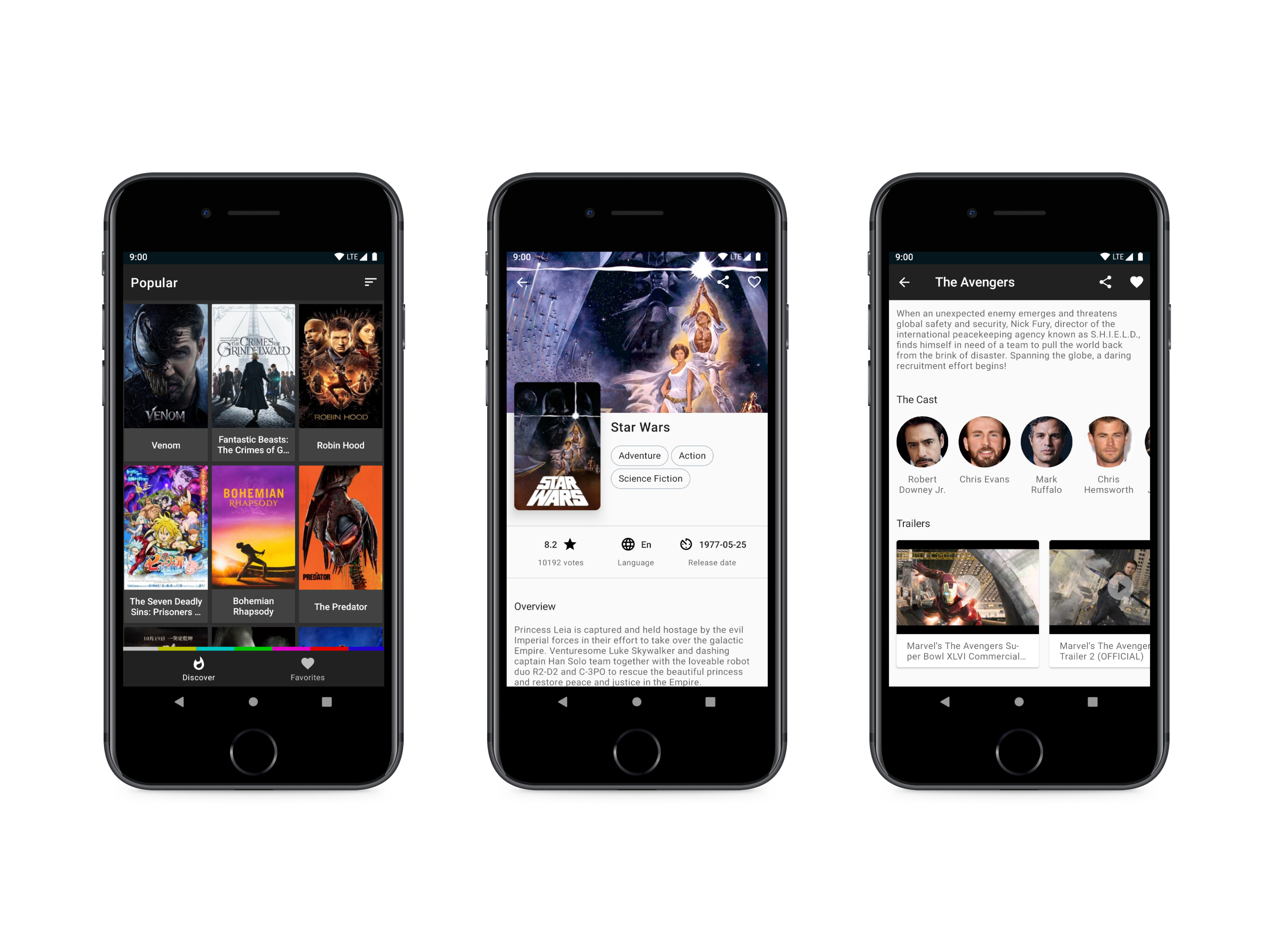
Osmunda is an Android library that reads open street map data (osm.pbf, osm.bz2 and osm.gz formats, the latter two are essentially xml), is written to SQLite, and can be used for offline geocoding, etc.
Osmunda is the scientific name of a genus of plants, it's a kind of fern, which was chosen because it starts with OSM.
Development progress
pre-release
To-do
- Try to use NOSQL database, because OSM data uses a lot of key-value pairs, so NOSQL database may be a better choice.
- Change method of obtaining administrative divisions in
Address().
How to use
Gradle Settings
Step 1.
Add the JitPack repository to your project build.gradle file:
allprojects {
repositories {
...
maven { url 'https://jitpack.io' }
}
}
Step 2.
Add the dependency
dependencies {
implementation 'moe.sunjiao:osmunda:
'
}
Import
For data Source, see OSM data website
Instantiate an OsmosisReader.
val reader: Reader = OsmosisReader()
Set import relations and ways data, if you don't need them, please do not write the following code. See Storage
reader.options.add (ImportOption.INCLUDE_RELATIONS) // Import relationa data
reader.options.add (ImportOption.INCLUDE_WAYS) // Import ways data
Set the commit frequency, otherwise the default setting (5,000) will be used. See commitFrequency
(reader as OsmosisReader).commitFrequency = 5000
Set the OSM data file or Uri(android.net.Uri), context and database file name, and start reading.
val file = File(requireContext (). filesDir.absolutePath + "/hubei-latest.osm.pbf")
reader.readData(file, requireContext (), "hubei")
//filename context database filename(excepted)
reader.readData(uri, requireContext (), "hubei")
//android.net.Uri context database filename(excepted)
Get import status
Use reader.read to get the number of OSM records read, and reader.insert to get the number of OSM records inserted into the database. (For the reason of difference between them, please refer to commitFrequency )
Use reader.progress to get the current estimated progress as a percentage.
Get a list of existing databases
Use Osmunda(requireContext()).GetDatabaseList() to get the list of imported databases.
Use Osmunda(requireContext()).GetDatabaseByName(databaseName) to get a specific database based with the name.
Geocoding
Use the search function of the Geocoder class to search. You can specify LIMIT and OFFSET in the database when searching, and you can also specify the range of latitude and longitude.
For example, searching for "Central China Normal University" within the scope of Wuhan, LIMIT 10 result, without setting OFFSET:
val hubeiDatabase: SQLiteDatabase = Osmunda(requireContext()).getDatabaseByName("hubei")
val list: List<SearchResult> = Geocoder(hubeiDatabase).search("Central China Normal University", 10, 0, 30.7324, 114.6589, 30.3183, 114.0588)
If you don't set the range, all records in the database will be searched:
val list2: List<SearchResult> = Geocoder(hubeiDatabase).search("Central China Normal University", 10, 0)
If you are searching on the map, you can directly pass the BoundingBox of the current MapView:
val box : BoundingBox = mapView.boundingBox
val list3: List<SearchResult> = Geocoder(hubeiDatabase).search("Central China Normal University", 10, 0, box)
Reverse geocoding
Use the search function of the ReverseGeocoder class to search. You can specify LIMIT and OFFSET in the database when searching.
val list: List<SearchResult> = ReverseGeocoder(hubeiDatabase).search(30.51910, 114.35775, 10, 0)
You can directly pass the Android Location or Osmdroid GeoPoint and IGeoPoint as parameters:
val location : Location = Location(GPS_PROVIDER)
val list2: List<SearchResult> = ReverseGeocoder(hubeiDatabase).search(location, 100, 0)
val geoPoint : GeoPoint = GeoPoint(30.51910, 114.35775)
val list3: List<SearchResult> = ReverseGeocoder(hubeiDatabase).search(geoPoint, 100, 0)
val iGeoPoint : IGeoPoint = mapView.mapCenter
val list4: List<SearchResult> = ReverseGeocoder(hubeiDatabase).search(iGeoPoint, 100, 0)
Get full address
You can use result.toAddress() to get an address, and then get the complete address from the returned Address class, you can also get the country, region, city, road, house number and other information.
for (result in list) {
val address : Address = result.toAddress()
val fullAddress : String = address.fullAddress // full address
val country : String = address.country // country
val state : String = address.state // province or state
val city : String = address.city // city
val county : String = address.county // district, county
val town : String = address.town // little town
val street : String = address.street // road, street
val housenumber : String = address.housenumber // house number
val neighbourhood : String = address.neighbourhood // community, school, institution, village, etc.
val housename : String = address.housename //
val postcode : String = address.postcode // postcode
val phone : String = address.phone // phone number
val website : String = address.website // website
}
Performance
Test devices: Google Pixel 3, Android Q (10.0)
Test files: hubei.osm.pbf, rhode-island.osm.bz2
The following data are measured in above environment.
Storage
The pbf file size of Hubei Province is 11.64 MiB (17,237,672 bytes), which contains 2,417,117 elements, converted into 5,505,162 database records.
The decompressed database file is 273.91 MiB (287,219,712 bytes), approximately 16.78 times of pbf.
The osm.bz2 file size of Rhode Island is 21.9 MiB (23,009,830 bytes), which contains 1,897,371 elements, converted into 4,525,039 database records.
The decompressed database file is 198.67 MiB (208,318,464 bytes), approximately 9.05 times of osm.bz2.
The data file in a large areas is not necessarily larger than ones in small areas, it is also infected by the local population, density of human settlements, and economic development. It is also related to the availability of Open Street Map services. For example, Guangdong is a populated and developed province and it has 73M of data, while the sparsely populated Xinjiang and Tibet only have 17M and 18M of data (all in pbf format). Please arrange your application according to the actual size of the data. If there is no available data, you can go to overpass-api https://overpass-api.de/api/map?bbox=min_longitude,min_latitude,max_longitude,max_latitude.
You can also choose whether to import relation data and way data according to the needs of your application. For the specific code, see Import
commitFrequency
Since the read operation occurs in the Osmosis instead of Osmunda, the OsmosisReader class in Osmunda is only called after the Osmosis reads an element. The process() function cannot be included in the same transaction.
In order to avoid the high time consumption caused by frequent begining and ending of transactions when inserting data one by one, the commitFrequency variable was set in the OsmosisReader class. When the records to be inserted reaches the number specified by commitFrequency, a Transaction will be opened for batch insert operations.
Before inserting, all currently read pending records are in memory. If the commitFrequency is too high, too much memory will be occupied; and if the commitFrequency is too low, the transaction begining and ending will be carried out frequently, very long time will be consumed.
The default value of commitFrequency is 5,000, you can modify it in your code according to the environment of your application.
Time
Database operation
In terms of read and insert operations, the reading speed of the pbf file is much faster than the XML format. It takes about 0.3-1 seconds to read 250,000 pieces of data, and it takes 5-15 seconds to read the same size of XML data. Inserting 250,000 pieces of data takes 4-7 seconds, regardless of the file format.
In terms of total time consumption, when commitFrequency is set to 1,000 ~ 500,000, the export time of Hubei Province's pbf file is about 2 minutes, and the export time of Rhode Island's osm.bz2 file is about 4 minutes, too small or too large commitFrequency will cause the operation to take a long time, and even almost impossible to complete.
Geocoding
The query operation of reverse geocoding takes 3-5 seconds, and the operation of obtaining the complete address according to the query result takes 0.3-3 seconds. If you query multiple geographic information records at one time, please do not get all the complete addresses at once, but do it when the user accesses a certain record.
CPU
The CPU usage of data read and database write operations is about 10% -30%.
Memory
The memory consumption of data read and database write operations is about 200M-1G.
OSM_data_website
Planet OSM is the original source of all data, operated by the Open Street Map, but its download speed is limited.
It can be downloaded from other mirror data websites: Site List
You can also export the xml file of specific area by yourself: https://overpass-api.de/api/map?bbox=min_longitude,min_latitude,max_longitude,max_latitude .
Please use files in pbf format as much as possible, because of its significant advantages in space occupation and time-consuming of import.
License
Copyright (C) 2020 SUN JIAO (https://www.sunjiao.moe)
Apache License Version 2.0, January 2004
http://www.apache.org/licenses/
References & Credits
Thanks to spyhunter99/osmreader, I referred to the project, rewrote its core algorithms in kotlin, fixed the Osmosis not work problem, and added reverse geocoding feature.
My OSM Account
sun-jiao, mainly active in Wuhan.
 1 Jun 24, 2022
1 Jun 24, 2022

 85 Dec 28, 2022
85 Dec 28, 2022
 7 Jul 30, 2022
7 Jul 30, 2022

 15 Dec 28, 2022
15 Dec 28, 2022
 4 Sep 17, 2021
4 Sep 17, 2021
 21 Nov 14, 2022
21 Nov 14, 2022
 1 May 24, 2022
1 May 24, 2022
 19 Dec 10, 2022
19 Dec 10, 2022

 109 Nov 18, 2022
109 Nov 18, 2022

 2 Oct 29, 2022
2 Oct 29, 2022

 4.3k Dec 31, 2022
4.3k Dec 31, 2022
 2 Apr 8, 2022
2 Apr 8, 2022
 112 Dec 9, 2022
112 Dec 9, 2022

 2 Aug 31, 2022
2 Aug 31, 2022

 13 Aug 16, 2022
13 Aug 16, 2022
 189 Nov 26, 2022
189 Nov 26, 2022

 3 Oct 19, 2022
3 Oct 19, 2022
 75 May 21, 2022
75 May 21, 2022

 247 Dec 27, 2022
247 Dec 27, 2022
 17 Oct 24, 2022
17 Oct 24, 2022
 0 Nov 30, 2021
0 Nov 30, 2021
 87 Sep 18, 2022
87 Sep 18, 2022
 39 Jul 15, 2022
39 Jul 15, 2022
 408 Dec 15, 2022
408 Dec 15, 2022
 1.6k Dec 29, 2022
1.6k Dec 29, 2022
 63 Mar 7, 2021
63 Mar 7, 2021
 3.4k Dec 30, 2022
3.4k Dec 30, 2022
 7 Aug 31, 2022
7 Aug 31, 2022